

本文介绍了 zk-SNARK 技术的工作原理和难点、多项式以及多项式承诺如何让 zk-SNARK 的实现更加高效
来源 |vitalik.ca
作者 |Vitalik Buterin
特别感谢 Georgios Konstantopoulos、Karl Floersch 以及 Starkware 团队的反馈和校对。
在 L2 扩容探讨中经常会出现的话题是“layer3(L3)”这个概念。如果我们可以构建一个锚定 L1 安全性并在其之上增加可扩展性的 L2 协议,那么我们也一定可以构建一个锚定于 L2 安全性并在其之上增加更多可扩展性的 L3 协议,以此实现更多扩容?
简要地说,这种观点是这样的:如果你拥有一个能够让你进行二次方扩容的方案,那你可以将这个方案构建在它自己之上,然后达到指数级的扩容吗?
我在自己 2015 年的可扩展性论文、Plasma 论文中的多层扩容想法等地方都讲到了类似的观点。不幸的是,这种关于 L3 的简单构思并不能像上述观点那样轻易实现。
这种方案的设计中总是会有一些无法直接堆叠的东西,只能在可扩展性上带来一次提升 —— 因为数据可用性的限制,紧急提款依赖于 L1 宽带等多种问题。
如 Starkware 提议的框架等较新的关于 L3 观点变得更复杂:这些 L3 方案不只是在自己的网络之上堆栈叠相同的方案,而是为 L2 和 L3 分配不同的用途。这种方法的一些形式可能会是好主意 —— 如果它能够以正确的方式实现。本文将会详细介绍在三层架构下哪些可能有意义,而哪些可能无意义。
(译者注:上述 StarkWare 文章中文版《分形式扩容:从 L2 到 L3》)
为什么无法通过将 rollup 堆叠在 rollup 之上一直扩容
rollup(在这里阅读关于 rollup 更长的文章。译者注:链接文章中文版《Vitalik:Rollups 不完全指南》)是结合各种技术解决区块链运行中两大主要扩展瓶颈的扩容技术:计算和数据。计算可以通过欺诈证明或是 SNARK(译者注:链接文章的中文版在这里)解决,两种方式依赖于很少的行动者就能对每个区块进行处理和验证,只需要其他参与者运行一小部分的计算来检查证明过程是否正确完成了。
这些方案尤其是 SNARK 几乎可以无限地扩展,你真的就可以通过保持构建“在一个 SNARK 证明之上构建多个 SNARK 证明”,为单个证明扩展更多算力。
数据则不同。rollup 使用许多压缩技巧来减少一笔交易在链上存储所需的数据量:一笔简单的货币转账从大约 100 字节减至大约 16 字节,兼容 EVM 的链上的一笔 ERC-20 代币转账从大约 180 字节减至 23 字节左右,而一笔保护隐私的 ZK-SNARK 交易可以从 600 字节左右压缩至 80 字节左右。
基本所有情况下的数据都能压缩至原来的 1/8。但是,rollup 还是需要在某一中介上让数据具有链上可用性,保证用户能够进行访问和验证,因此,用户可以自主地计算 rollup 的状态,并在现有证明生成者下线的情况下作为证明生成者加入证明过程。
数据只能压缩一次,无法再次压缩 —— 如果数据可以再次压缩,那么通常有一种方式将第二个压缩器的逻辑放入第一个的逻辑中,只要压缩一次就能让第二个压缩器或跟第一个压缩器相同的效果。所以说,事实上“在 rollup 之上构建 rollup”并不能在可扩展性方面提供巨大的收益 —— 不过,这种模式可以用于其他的用途,正如下面我们将看到的一样。
所以“合理的” L3 版本是什么样的?
好吧,让我们一起看看 StarkWare 在关于 L3 的文章中倡导的是什么(译者注:该文章的中文版在上面)。StarkWare 团队由非常聪明且实际上理智的加密学家所组成,所以如果他们倡导 L3,那么他们的观点会比“如果 rollup 的数据压缩至 1/8,那么很明显,构建于 rollup 之上的 rollup 会将数据压缩为原来的 1/64”的观点更为复杂。
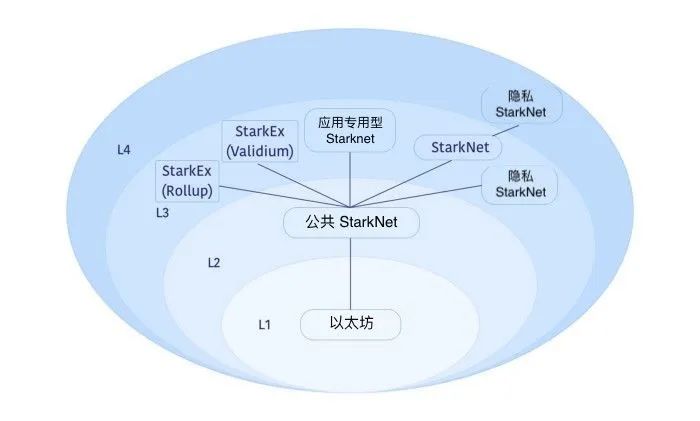
这是 StarkWare 文章中的图表:

以下是一些引用:
第一张示例图中描述了这样一种生态系统的例子,其 L3 包括:
●使用 Validium 数据可用性方案的 StarkNet,比如,为定价上具有极度敏感性的应用程序提供多种用途。
●应用专用型 StarkNet 系统可以定制更好的应用程序性能,比如,通过采用指定的存储结构或数据可用性压缩方式。
●使用 Validium 或 Rollup 数据可用性解决方案的 StarkEx 系统(比如那些服务于 dYdX、Sorare、Immutable 和 DeversiFi 的系统),会很快地为 StarkNet 带来经过长期考验的可扩展性效果。
●隐私 StarkNet 的例子(在这个例子中也作为 L4)可以在不将交易打包至公共 StarkNet 的情况下进行隐私保护交易。
我们可以将这篇文章压缩为“L3s”的三个愿景:
-
L2 用于扩容,L3 用于定制功能,如隐私。这个愿景的 L3 无意于提供“可扩展性平方”;不如说,会有一层堆栈帮助应用程序进行扩展,然后还有一些独立的堆栈层用于满足不同用例定制功能的需求。
-
L2 用于通用型扩容,L3 用于定制型扩容。定制型扩容可能会有不同的形式:专用型应用可以使用 EVM 以外其他虚拟机来进行计算, rollup 的数据压缩也会围绕定制型应用程序的数据结构进行优化(包括将“数据”从“证明”中分离出来,并使用每个区块中的单个 SNARK 完全替换掉这个区块中所有的交易证明)。
-
L2 用于去信任扩容(如 rollup),L3 用于弱信任扩容(如 Validium)。Validiums 指使用 SNARK 验证计算结果的系统,但是它将数据可用性放在了受信任的第三方或委员会处。在我看来,Validium 被大大低估了:尤其是,运行 Validium 证明生成器并定期提交哈希上链的中心化服务器也许真的可以很好地服务于许多“企业区块链”应用程序。Validium 的安全性指数比 rollup 低,但是相较之下便宜很多。
在我看来,这三种愿景本质上是合理的。“专用型/定制型数据压缩服务需要有自己的平台”的想法可能是所有主张中最不能令人信服的 —— 设计一个通用型基础层压缩方案 L2 很容易,因为用户可以使用应用专用型的子压缩器进行扩展 —— 而除此之外的用例都是合理的。但这还是留下了很大的疑问:三层结构是实现这些目标的正确方式吗?将 Validium、隐私系统和定制型环境锚定 L2 而不仅仅锚定 L1 的意义在哪?这个疑问的答案很复杂。
哪一个更好?
存款和提款在 L2 的子树(sub-tree)中会变得更便宜、更容易吗?
这种三层模型优于两层模型的一个论证可能是:三层模型允许整个子生态系统存在于单个 rollup 中,这让生态系统内的跨域操作可以非常便宜地进行,不需要经由昂贵的 L1。
但事实证明,即使是向同一个 L1 提交数据的两个 L2(甚至 L3)之间,存款和提款也可以很便宜!关键是要意识到,代币和其他资产不一定非得在底部链中发行。换句话说,你可以在 Arbitrum 上持有一种 ERC20 代币,然后在 Optimism 上创建它的封装合约,并在两者之间来回转移资产而无需创建任何 L1 交易!
让我们来看看这样一个系统如何进行运作。现在有两种智能合约:Arbitrum 上的基础合约和 Optimism 上的代币封装合约。要从 Arbitrum 转移资产到 Optimism,你需要将代币发送到基础合约,这会生成一个收据。一旦 Arbitrum 敲定了这笔交易,你就可以获取该收据的 Merkle 证明,它植根于 L1 状态,并将其发送到 Optimism 上的代币封装合约中。封装合约会对它进行验证并向你发放封装代币。要将代币往回转移的话,则可以反向执行相同的操作。
尽管证明 Arbitrum 存款所需的 Merkle 路径会检查 L1 的状态,但 Optimism 只需要读取 L1 状态根以处理存款 —— 不需要创建 L1 交易。请注意,由于 rollup 数据是最稀缺的资源,所以此类方案的可行实现将是使用 SNARK 或 KZG 证明以节省空间,而不是直接使用 Merkle 证明。
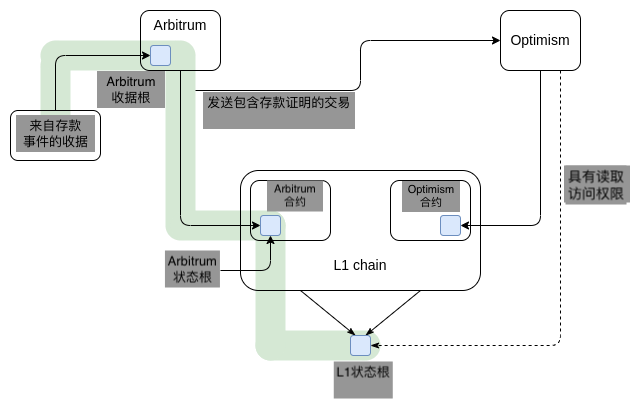
对比根植于 L1 的代币,这种方案有一个关键的弱点,至少在 optimistic rollup 上有这样的问题:存款也需要等待欺诈证明的窗口期到来。如果代币是在 L1 上的,那么从 Arbitrum 或 Optimism 上往 L1 的提款则需要一周的延迟时间,而存款则是即时的。
然而,这种方案中的存款和提款都需要一周时间。也就是说,尚不清楚 optimistic rollup 上三层架构是否会更好:因为要确保欺诈证明博弈会在一个自己运行欺诈证明机制的系统内安全地进行,这存在很多技术上的复杂性。
幸运的是,这些问题都不会在 ZK rollup 上出现。出于安全方面的原因,ZK rollup 不会要求一周时长的等待窗口,但他们确实还会有较短窗口期的要求(第一代技术可能需要 12 个小时的等待期)。
原因有二,首先,特别是更复杂的通用型 ZK-EVM rollup 需要较长的时间来囊括区块证明过程中的不可并行计算时间;其次,这其中还有经济考量:需要不那么频繁地提交证明以最大程度减少证明交易相关的固定开销。包括专用型硬件在内的下一代 ZK-EVM 技术将会解决上述的第一个问题,而架构更好的 batch 验证技术可以解决第二个问题。这其实是我们接下来会讨论的优化和批量提交证明的问题。
rollup 和 validium 的确认期 vs. 固定开销权衡。L3 们可以帮忙解决这个问题,但还有哪些方案可以帮忙解决?
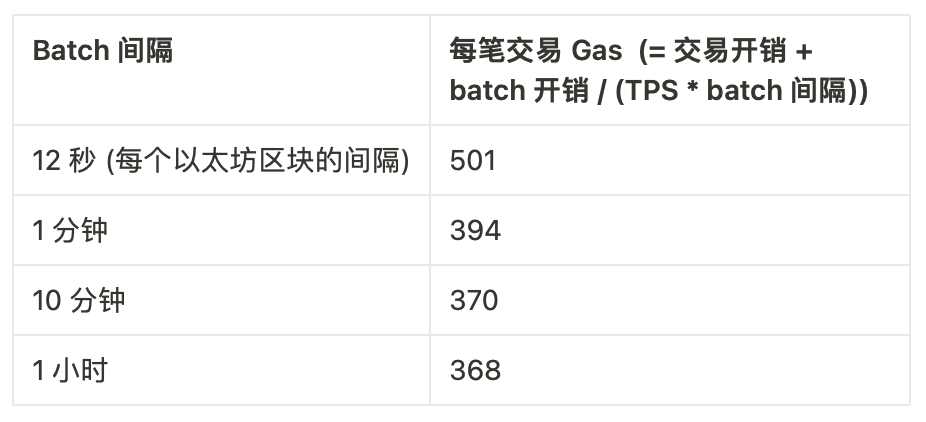
rollup每笔交易的开销很便宜:只有 16 – 60 字节的数据,这取决于所使用的应用程序。但是 rollup 也必须在每次提交一个 batch 的交易至链上时支出一笔高昂的固定开销:optimistic rollup 的每 batch 要支付 21000 L1 gas,而 ZK rollup 则要支付 400,000 gas 以上(如果你只想使用 STARK 这种量子安全的技术,可能会需要支付上百万 gas)。
当然,rollup 可以选择等着,直到有了价值 1 千万 gas 的 L2 交易再打包提交 batch ,但这会让 rollup 的 batch 间隔变得很长,迫使用户在获得高安全性确认之前等待更长的时间。因此,它们会有权衡:长时间的 batch 间隔和最优开销,或者说较短的 batch 间隔和大大增加的开销。
为了给出一些具体的数据,让我们一起探讨这样一个 ZK rollup:它每 batch 开销 600,000 gas,能处理完全优化过的 ERC-20 转账(23 字节),每笔交易会花费 368 gas。假设这种 rollup 在采用的早期和中期阶段的平均每秒交易(TPS)为 5 笔。我们可以计算它的每笔交易的 gas vs. batch 间隔:
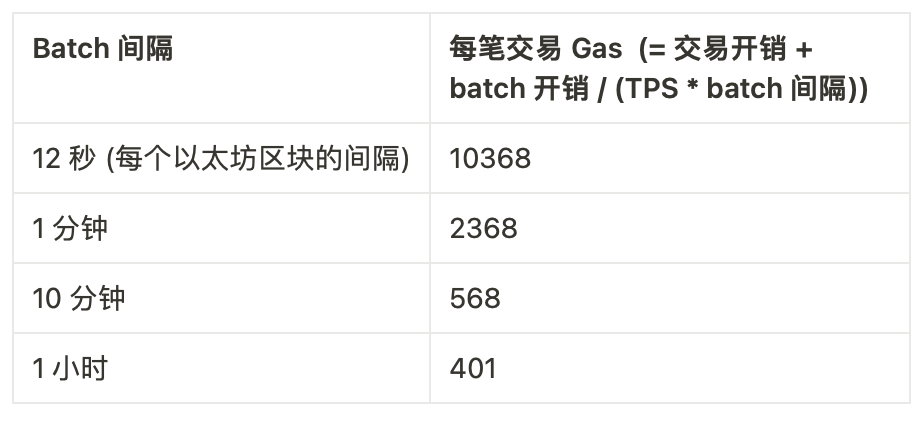
如果我们进入一个有着许多定制型 validium 和应用专用型环境的系统,那么它们中的大多数都不会处理超过 5 TPS。所以,在确认时间和开销之间的权衡开始变得至关重要。而实际上,“L3” 范式确实可以解决权衡上的问题!就算是以简单的方式实现,一个 ZK rollup 套着另一个 ZK rollup 的方案也大约会有仅 8000 L1 gas 左右的固定开销(证明占 500 字节)。这就将上面的表格改为:
开销的问题基本上都解决了。那么,L3 是不是有益的?可能吧。但值得注意的是,还有一种可以解决这个问题的方法,这个方法受到了 ERC 4337 聚合验证的启发。
其对策如下。现在,如果每一个 ZK rollup 或 validium 收到了证明 Snew=STF(Sold,D) 的证明,即新的状态肯定是正确处理了交易数据或旧状态根上状态变换的结果,那它们就会接收状态根。
在这个新的方案中,ZK rollup 会从 batch 验证器合约处接收消息,这个消息用于告知该验证器已验证了一个包含声明的 batch 证明,其中的每个声明都是 Snew=STF(Sold,D) 的形式。该 batch 证明可以通过递归 SNARK 方案或是 Halo 聚合进行构造。
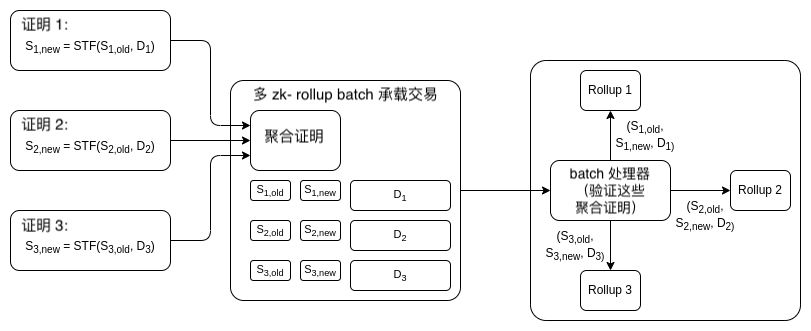
这是一个开放协议:任何 ZK-rollup 都可以加入,任何 batch 的证明生成者都可以从任何兼容的 ZK-rollup 中聚合证明,并从聚合器处获得交易费的补偿。batch 处理器合约会验证一次证明,接着将包含该 rollup $(S_{old},S_{new},D)$ 三元组(triple)的消息传递至每一个 rollup;三元组来自 batch 处理器合约的事实会是交易有效性的证据。
如果优化得不错,那么这个方案中每个 rollup 的开销则将近 8000 gas:5000 用于写入新添加的更新状态,1280 用于旧状态根和新状态根,还有剩下的 1720 用于有效利用各种数据。所以说,这种方案也能节省开销。
StarkWare 实际上已经有了类似的方案,叫做 SHARP,尽管它还不是一个无需许可的开放协议。
对于这类方法的反应可能会是:但这不就是另一种 L3 方案吗?比起 base layer <- rollup <- validium(基础层 ← rollup ← validium)结构,你有 base layer <- batch mechanism <- rollup or validium(基础层 ← batch 机制 ← rollup 或 validium)。
从一些哲学的建筑角度来看,这可能是事实。但这里有一个重要的区别:比起将中间层作为复杂完整的 EVM 系统,还不如说它是简化且高度专业化的对象,所以它更可能是安全的,也更可能在还完全不需要其他专门的代币的情况下构建起来,还更可能实现治理最小化且不会随着时间改变。
总结:实际上什么是“层”?
在其自身网络之上的堆叠相同扩容方案的三层扩容架构通常无法很好地运作。构建于 rollup 之上的 rollup,这两层 rollup 当然不会使用相同的技术。
但是,可以使用第二层和第三层具有不同用途的三层架构。构建于 rollup 之上的 Validium 确实是有意义的,即使无法确定它们是否会是长期的最佳运作方式。
然而,一旦开始深入了解哪种架构有意义,我们就会陷入哲学问题:什么是“层”,什么不是?base layer <- batch mechanism <- rollup or validium(基础层 ← batch 机制 ← rollup 或 validium)模式与 base layer <- rollup <- rollup or validium (基础层 ← rollup ← rollup 或 validium)模式执行着相同的工作。
但在工作方式方面,证明聚合层看起来更像是 ERC-4337,而不是 rollup。通常,我们不会将 ERC-4337 称为 “L2”。同样,我们不会将 Tornado Cash 称为“第 2 层” —— 所以如果要保持归类上的一致,我们不会将构建于 L2 之上的以隐私为中心的子系统称为第 3 层 。因此,关于什么对象应该首先被称为“层”,这存在一个未解决的语义争论。
关于这个问题,可能有很多思想流派的不同看法。我个人偏向则会是保持 L2 这个术语限定于具有以下特点的事物:
-
其用途在于增加可扩展性
-
它们遵循着“处于一条区块链中的区块链”模式:它们有自己处理交易和内部状态的机制
-
它们完全继承了以太坊区块链的安全性
所以,optimistic rollup 和 ZK rollup 是 L2,但是 validium、证明聚合方案、ERC-4337、链上隐私系统和 Solidity 则属于其他方案。可能把这些方案中的一部分称为 L3 是说得通的,但也许不能全都称作 L3;任何情况下,在多 rollup 生态系统的架构确定下来之前就为其下定义可能为时过早了,而大部分讨论也只是在理论上。
也就是说,语言上的争论远不如“哪个结构实际上最有意义”这种技术问题来得重要。显然,服务于隐私等非扩容需求的某种“层”可以发挥重要作用,并且显然需要以某种方式填补重要的证明聚合功能,最好由开放协议来填充这个位置。
但与此同时,我们有充分的技术理由,让连接着面向用户的环境和 L1 之间的中间层尽可能变得简便;在许多情况下,将 “粘合层” 作为 EVM rollup 可能不是正确的运作方法。随着 L2 扩容生态系统的成熟,我猜本文中描述的更复杂(和更简单)的结构将开始发挥更大的作用。
{kind=link}