

中心化 Rollups 最终将面临垄断定价和 MEV 的问题。此外,中心化 Rollups 本质上会破坏可组合性,导致割裂的 Rollups。
撰文:Scroll
随着 Rollups 使用的增加并托管生态的应用程序,用户的迁移成本将增加,中心化的排序器将获得对定价的垄断性影响力。中心化排序器的控制者有理由从用户中直接(例如通过费用)和间接(例如通过抢跑交易、三明治攻击等)最大程度地提取价值(MEV)。— Espresso
正如 Espresso 团队所提到的,中心化 Rollups 最终将面临垄断定价和 MEV 的问题。此外,中心化 Rollups 本质上会破坏可组合性,导致割裂的 Rollups。
然而,目前几乎所有的 Rollups 都仍然是中心化的,因为建立一个去中心化、无需许可且可扩展的 Rollup 是极具挑战性的。另一个原因是,先推出中心化的 Rollups 可以帮助孵化生态系统并抢占市场份额。
而当我们讨论去中心化的 Rollups 时,特别是 zkRollups 时,有两个层面的去中心化。第一个是证明者的去中心化,第二个是排序器的去中心化。实现完全的去中心化,还需要解决排序器和证明者之间的协调问题。
在模块化趋势下,去中心化 Rollup 目前主要有三类参与者。第一类旨在实现完全去中心化的 Rollups,并提出了完整的解决方案。第二类是旨在解决证明者网络的协议。最后有多种解决方案正在实现排序器的去中心化。
Rollups 去中心化


在 zkRollups 中,Polygon 和 Starknet 已经提出了解决方案来实现他们 Rollups 的去中心化。
Polygon

在引入 POE(Proof of Efficiency)之前,Polygon zkEVM 采用了 POD(Proof of Donation),使得排序器可以竞标创建下一个交易批次的机会。但是,这会带来一个问题,即单个恶意方可以通过出价最高来控制整个网络。
采用 POE 后,排序器和证明者将在自身硬件条件下,最高效地参与到无需许可的网络中。任何人都可以加入 Polygon zkEVM,只要这是有经济效益的。
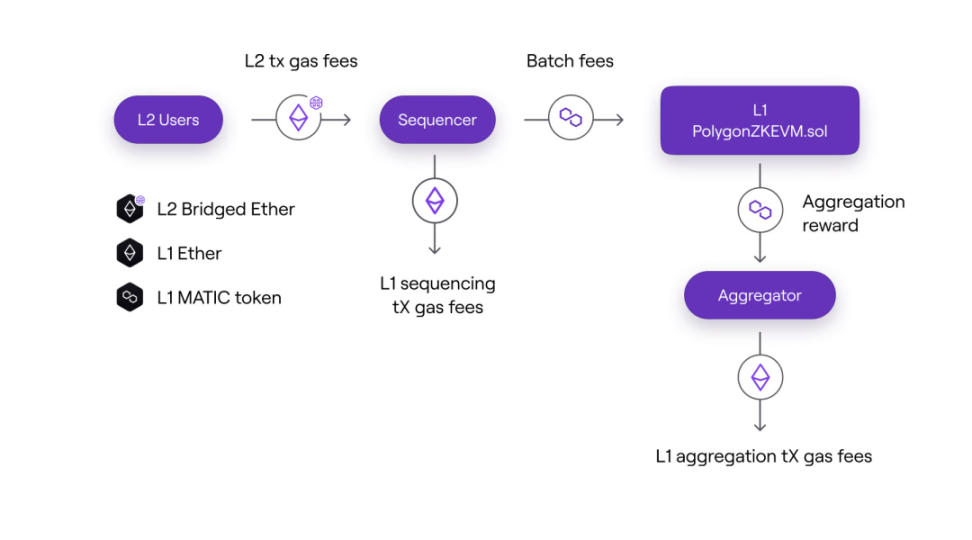
在 Polygon zkEVM 中,排序器需要 16GB 的 RAM 和 4 个核心的 CPU,而证明者需要 1TB 的 RAM 和 128 个核心的 CPU。此外,还有一个称为聚合器的角色,负责收集 L1 数据,将其发送到证明者,接收证明并将其提交到 L1。我们可以将聚合器和证明者视为同一个主体,因为聚合器和证明者之间的关系是非常简单的,聚合器支付证明者生产证明的成本。
这种架构非常简单:任何排序器都可以无需许可地在 L1 上基于前一个状态打包交易,并更新相应地状态。同时,任何聚合器都可以提交证明以验证更新后的状态。
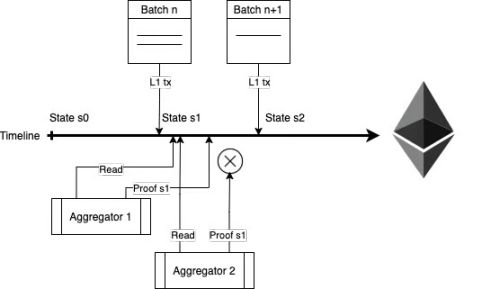
在 POE 中,效率不仅指参与者在相互竞争时的网络效率,也指排序器和证明者自身的经济效率。在 L2 中,排序器和证明者分享交易费用,排序器支付 batchFee 给聚合器来生成证明。这确保了参与者在经济上有动力为网络效率做出贡献,从而带来更加健壮和可持续的生态系统。
排序器
- 收入:L2 交易费用
- 成本:batchFee (以 $MATIC 计算)+ L1 交易费用(调用 sequenceBatches 方法)
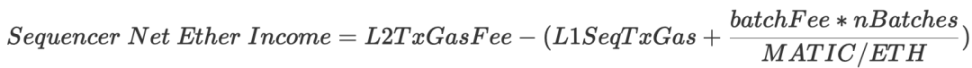
聚合器(证明者)
- 收入:batchFee (以 $MATIC 计算)
- 成本:证明成本 + L1 交易费用(调用verifyBatchesTrustedAggregator 方法)
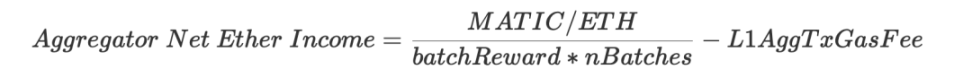
协调器: batchFee
- 初始参数
- batchFee= 1 $MATIC
- veryBatchTimeTarget = 30 分钟。这是验证批次的目标时间。协议将更新`batchFee`变量来达到该目标时间。
- multiplierBatchFee = 1002。这是批次费用乘数,范围从 1000 到 1024,保留 3 位小数。
- 调节器
- diffBatches : 被聚合的批次中> 30 分钟的数量减去<=30 分钟的批次数量。最大值为 12。
- 协调过程
- 当 diffBatches> 0 时,增加聚合奖励以激励聚合器。
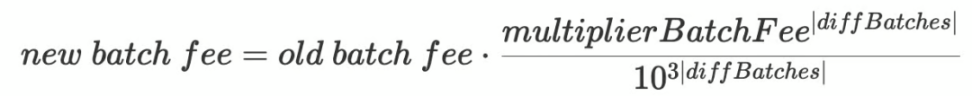
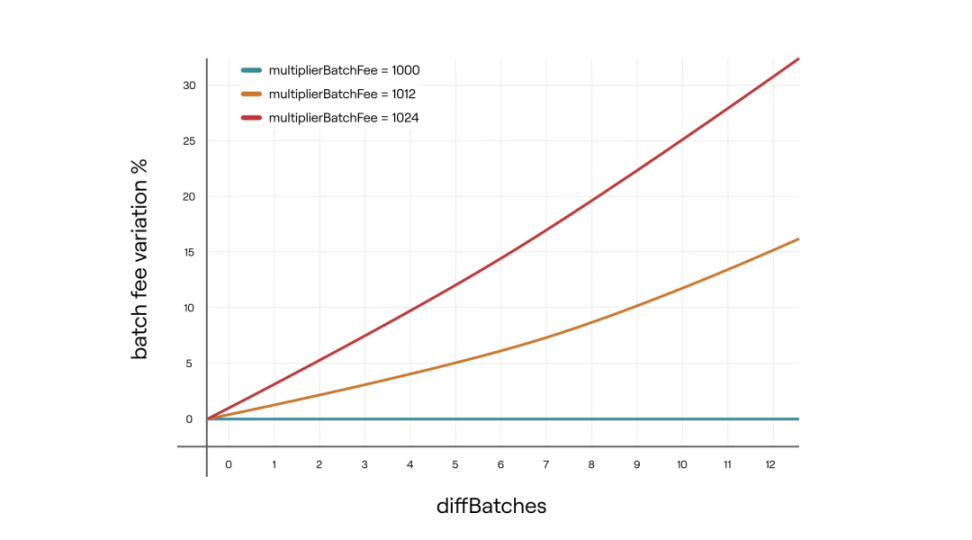
- 当 diffBatches < 0 时,减少聚合奖励来抑制聚合器,减缓聚合进程。
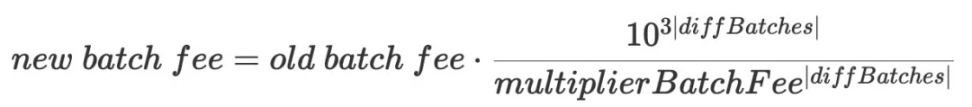
Starknet

Starknet 也旨在构建一个快速确认的无许可且可扩展的 Rollup。虽然尚未达成去中心化解决方案的最终规范,但他们几个月前在论坛上发布了一些草案。
与 Polygon zkEVM 的简单机制相比,Starknet 的方案更为复杂,因为它包括 L2 共识和证明网络中的链式协议证明(chained proof-of-a-protocol)。
排序器
Starknet 提出了一个双账本共识协议,而不是简单地在排序器层中添加一个共识层。在该协议中,L2 作为 live protocol 提供快速响应,而 L1 checkpoints 则作为 safe protocol 提供最终确认性。
对于 L2 的 live protocol,可以采用各种共识机制,例如抗女巫的 PoS 系统,如 Tendermint 或 DAGs。另一方面,L1 的 safe protocol 涉及多个合约,分别处理 Stake 管理、证明验证和状态更新。
该双账本共识协议的典型工作流程如下:
1. 首先,将 L2 live ledger 的输出作为 L1 safe ledger 的输入,生成一个检查后的 live ledger。
2. 然后,将检查后的 live ledger 作为输入,再次输入到 L2 的纯共识协议中,确保检查后的 live ledger 始终是 liveledger 的前缀。
3. 重复上述过程。
在构建双账本共识协议时,存在成本和延迟之间的权衡。理想的解决方案旨在同时实现低成本和快速的最终确认。
为了在 L2 上降低 gas 成本,Starknet 将 checkpoints 分为「分钟级」和「小时级」。对于「分钟级」 checkpoints,只有状态本身被提交到链上,而其余数据(有效性证明、数据可用性等)则通过 StarkNet L2 网络发送。这些数据由 StarkNet 全节点存储和验证。另一方面,「小时级」 checkpoints 在 L1 上进行公开验证。两种类型的检查点提供相同的最终确认。对于「分钟级」 checkpoints,有效性证明由 StarkNet 全节点验证,并可以由任何一个节点在 L1 上发布,以向「分钟级」 checkpoints 赋予 L1 的最终确认性。因此,证明者需要生成小证明,以便在 L2 网络中广泛传播。
为了进一步降低延迟,Starknet 提出了一种领导者选举协议,以提前确定领导者。其基本逻辑如下:当前时期 i 的领导者是基于 L1 质押数量和一些随机性预先确定的。具体来说,在时期 i-2 中,leader_election 方法根据时期 i-3 中的质押数量将排序器按词典顺序平铺展开。然后,发送一笔交易来更新随机数并随机选择一个点。该点落在位置所对应的排序器将成为时期 i 的领导者。
证明者
在 POE 模块下,参与者之间进行公开竞争,这可能导致赢家通吃的情况。Starknet 试图实现一种无中心化风险的竞争机制。以下是几种可选方案:
- 轮流制:这可以部分解决中心化问题,但可能无法通过激励机制找到证明工作的最佳人选。
- 基于质押:排序器根据其所质押的数量决定了当选证明者的概率。
- Commit-Reveal 方案:首个提交者需要抵押代币来获得短暂的垄断机会,然后在该时间窗口内生成证明。为了避免 DDoS 攻击,如果前者无法及时生成证明,后者所需的抵押代币将呈指数级增长。虽然在该机制下,网络可能会失去最佳性能的机器,但可以培养更多的证明者。
除了证明者之间的竞争,还应该降低进入门槛,以便更多的证明者可以参与到网络中来。Starknet 提出了一种利用递归证明的复杂协议,称为链式协议证明。
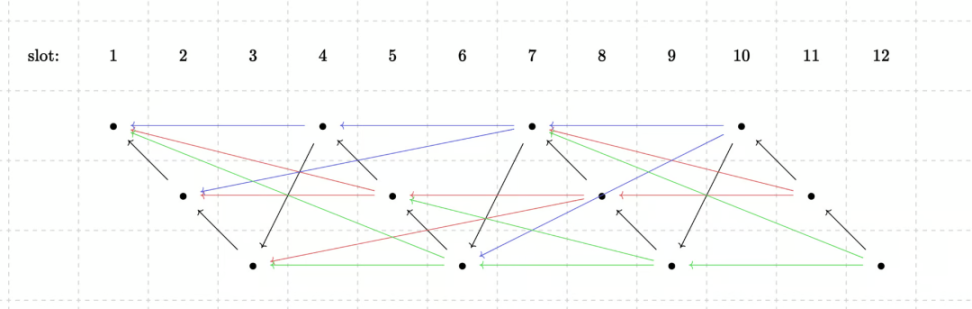
在链式协议证明中,区块链本身被划分为几个不同的分支。这样证明不仅可以是递归的,而且证明生成也可以是并发的。例如,在 3 个分支的设定中,12 个黑色的区块被分为 3 行,每行代表一个分支。我们可以把每个分支看作一个子链,子链中的每个块都应证明前一个块。从整条链的角度看,插槽 n 需要证明插槽 n-3 。3 个区块的间隔为排序器预留了足够的时间来提前计算和购买证明。这有点类似于分片技术,其中攻击者只需要控制一个分支就能控制整个证明者网络。
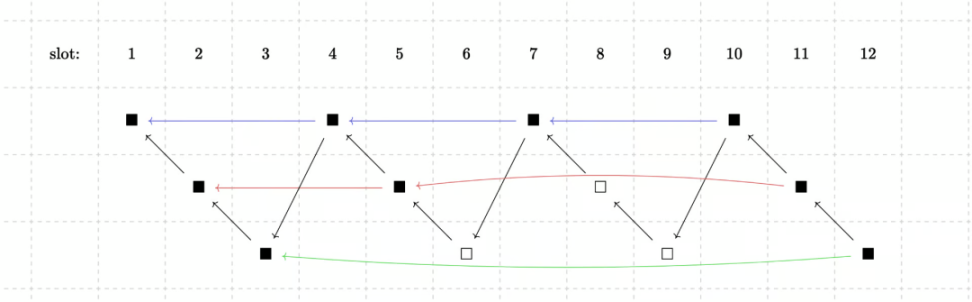
为了将这些分支编织在一起,Starknet 提出了一种编织技术,可以将多个节点合并在一起,共同验证交易的合法性,确保交易记录的一致性和可靠性。
其中一种方案是要求每个插槽需要同时与几个分支进行合并。另一种方案是将每个分支交替尝试和其余分支合并,从而减少证明工作量。当然这也是一个开放性问题,可能未来有更好的解决方案。
协调
为了积极确保证明者能够有足够的盈利空间,Starknet 提出了参考 EIP1559 方案的做法:将基础费用设定为证明者资源价格的下限,积极地进行价格发现,并且排序器可以使用小费来激励证明者。这样,证明者将始终得到超额支付,只有极端情况才会影响证明过程。否则,如果证明者获得的报酬接近市场价格,那么轻微的波动就可能引发证明者停摆。
证明者去中心化

从 Rollups 的角度来说,证明者比排序器去中心化更容易实现。而且,当前证明者是性能瓶颈,需要跟上排序器批处理的速度。在排序器去中心化尚未解决时,去中心化的证明者也可以为中心化的排序器提供服务。
事实上,不仅是 Rollups,zkBridge 和 zkOracle 也需要一个证明者网络。他们都需要一个强大的分布式证明者网络。
从长远来看,能够容纳不同计算能力的证明者网络更具可持续性,否则性能最好的机器将垄断市场。
证明市场
有些协议不是协调排序器和证明者之间的关系,而是直接将协调抽象成了证明市场。在该市场中,证明是商品,证明者是证明的生产者,而协议则是证明的消费者。在「看不见的手」的作用下,市场均衡是最高效的。
Mina

Mina 已经建立了一个名为 Snarketplace 的证明市场,在其中交易 Snark 证明。这里的最小单位是单个交易的 Snark 证明。Mina 采用了一种名为 Scan State 的状态树的递归证明。
Scan State 是一个二叉树的森林,其中每个交易是一个节点。在树的顶部生成一个单个证明,可以证明树中的所有交易。证明者有两个任务:首先是生成证明,第二是合并证明。
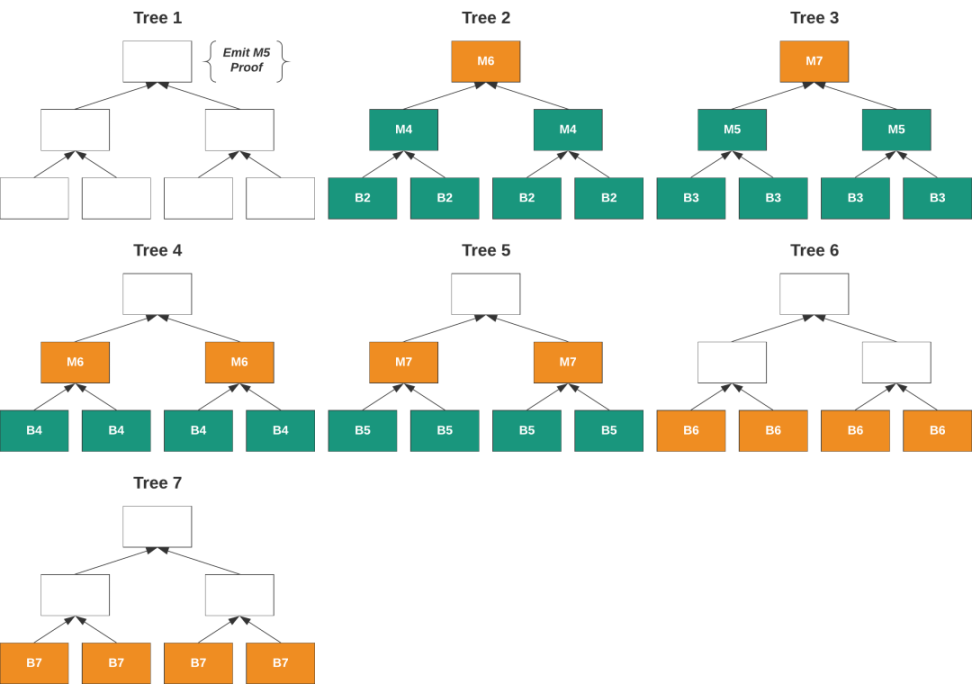
在证明者完成工作并提交出价后,Mina 协议的区块生产者将选择最低价格的出价者。这也是均衡价格,因为出价者会提交高于证明成本的出价,而区块生产者将不会购买不划算的证明。
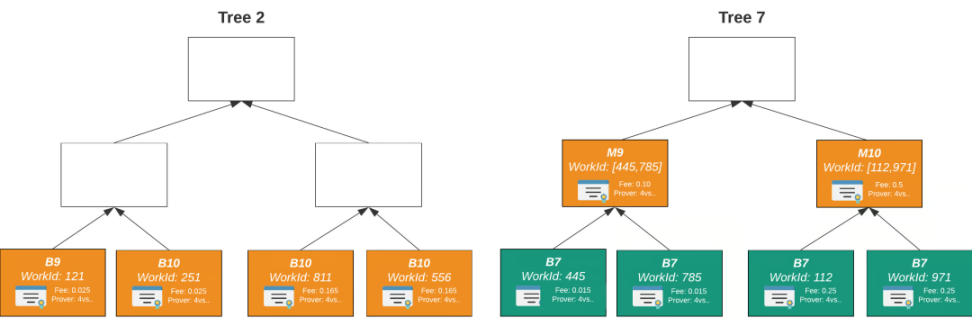
=Nil; Foundation

Mina 的证明市场是专为自己的协议设计的,而=nil; Foundation 则提出了一个通用的证明市场,以服务整个市场。
该市场的服务由三个组成部分构成:`DROP DATABASE、zkLLVM 和 Proof Market。
- DROP DATABASE:是一个数据库管理系统协议,可以看作是一个 DA 层。
- Proof Market:是一个在 DROP DATABASE 上运行的应用程序,类似于一些人所说的 zk 证明的「去中心化交易所」。
- zkLLVM:是一个编译器,将高级编程语言转换为可证明计算协议的输入。
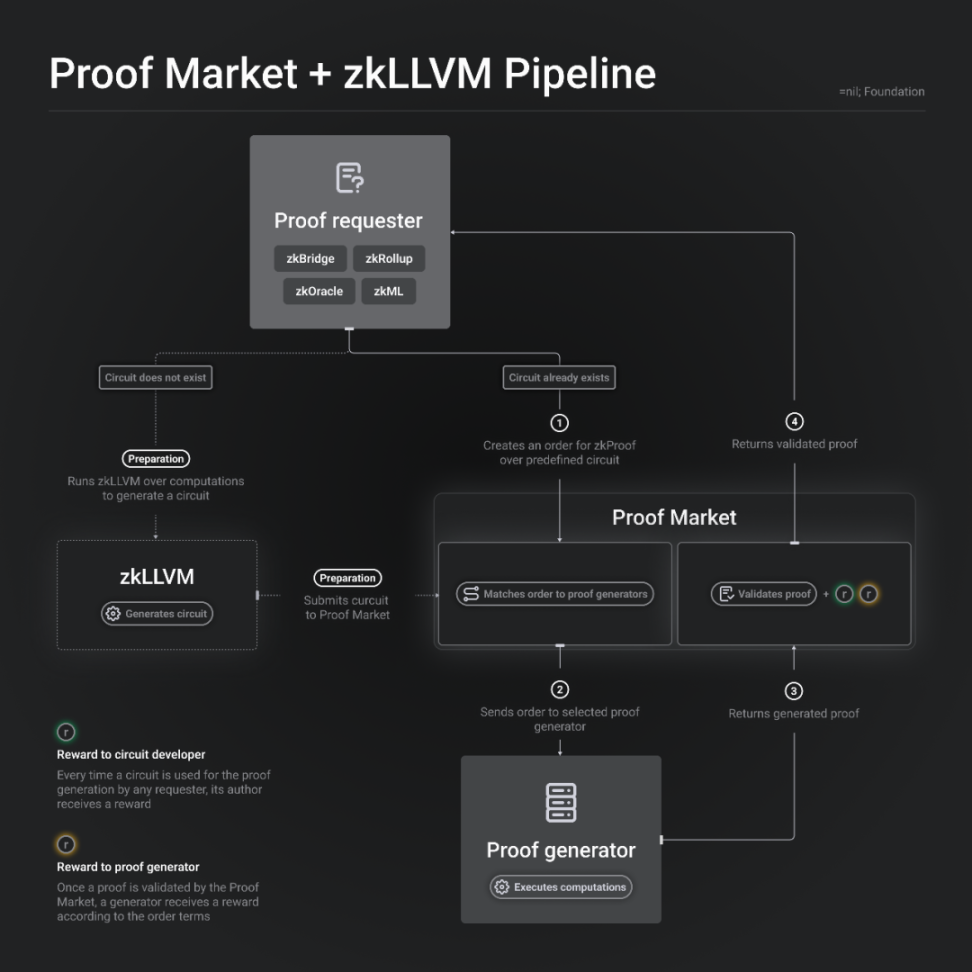
每个证明由其不同的输入和电路组成,因此每个证明都是唯一的。电路定义了证明的类型,类似于金融术语中定义「交易对」的方式。此外,不同的证明系统引入了更多的电路。
工作流程如下:证明的需求方可以用高级编程语言编写代码,然后通过工具链将其喂给 =nil; zkLLVM,生成一个单独的电路,它将成为市场中的一个独特的交易对。
对于证明需求方,他们可以在成本和时间之间做取舍。证明者也将考量自己的计算能力和收入。因此在市场上,将会有不同的计算能力,高算力将更快地生成证明,但成本更高,而低算力生成证明更慢,但更便宜。
两步提交

最近,Opside 提出了一种两步提交方案来去中心化证明者网络。该方案将证明提交分成两个阶段,来避免最快的证明者总是胜出的情况。
- 步骤 1:提交第 T 个区块的零知识证明的哈希
- 从第 T+11 个区块开始,不再允许新的证明者提交哈希。
- 步骤 2:提交零知识证明
- 在第 T+11 个区块之后,任何证明者都可以提交零知识证明。如果至少有一个零知识证明通过验证,它将用于验证所有提交的哈希,经过验证的证明者将根据抵押金额的比例获得相应的 PoW 奖励。
- 如果在第 T+20 个区块之前没有零知识证明通过验证,则所有提交哈希的证明者都会受到惩罚。然后重新开放排序器,可以提交新的哈希,回到步骤 1。
这种方法可以包容不同的算力。然而,所需的抵押仍然引入了一定程度的中心化。
排序器去中心化

排序器的去中心化比验证者更为复杂。这是因为排序器具有打包排列交易的权力,诸如 MEV 和收入分配等问题都需要考量。
考虑到以太坊将对活性的优先级高于响应性,L2 解决方案应该通过优先考虑响应性而不是活性来与这样的取舍互补。但是,与中心化排序器相比,去中心化排序器在响应性方面本身就有所牺牲。因此,需要实现各种优化来解决这个困境。
目前,有三种不同的去中心化排序器方案。第一种方案是通过优化共识机制实现。第二种方案涉及共享排序器网络。第三种方案基于 L1 的验证者。
共识

共识协议主要负责对交易进行排序和确保其可用性,而不是执行交易。但是,正如前面提到的直接添加另一个共识层,并不是一个简单的解决方案。
为了提高响应性,一种常见的方法是依靠较小的验证器集合。例如,Algorand 和 Polkadot 使用随机抽样的较小委员会来批量处理交易。所有节点使用随机信标和可验证随机函数(VRF),在给定时期内被包含在委员会中的概率与其质押数量成比例。
为了减少网络流量,可以使用更小的数据可用性(DA)委员会。或者采用 VID(Verifiable Information Dispersal)。VID 将数据的纠删码分发给参与共识的所有节点,使得任何持有足够高质押比例的节点子集都可以协作恢复数据。这种方法的取舍在于减少广播复杂性,但增加了数据恢复的复杂性。
Arbitrum 则选择了有声誉的实体组成验证者集,如 ConsenSys、Ethereum Foundation、L2BEAT、Mycelium、Offchain Labs、P2P、Quicknode、IFF 的分布式账本研究中心(DLRC)和 Unit 410 加入排序器委员会。这种方法的取舍在于通过提高去中心化的质量来弥补数量上的不足。

共享排序器网络

排序器在模块化区块链中(特别是在 Rollup 中)发挥着至关重要的作用。每个 Rollup 通常都会构建自己的排序器网络。然而,这种方法不仅造成了冗余问题,而且还阻碍了可组合性。为解决这个问题,一些协议提出了构建一个共享的 Rollup 排序器网络。这种方法降低了实现原子性、可组合性和互操作性的复杂度,这些特性在开放无需许可的区块链中,是用户和开发者迫切需要的。此外,它还不再需要单独的排序器网络的轻客户端。
Astria

Astria 正在为 Celestia 的 Rollup 生态系统开发一种中间件区块链,其中包括自己的分布式排序器集合。这个排序器集负责接受来自多个 Rollup 的交易并将其写入基础层,而不执行它们。
Astria 的作用主要聚焦于交易排序,与基础层和 Rollup 独立运作。交易数据存储在基础层上(例如 Celestia),而 Rollup 全节点维护状态并执行操作。这确保了 Astria 与 Rollup 解耦。
对于最终确认性,Astria 提供两个级别的 Commitment:
- Soft commitment:使得 Rollup 能够为其最终用户提供快速的区块确认。
- Firm commitment:速度与基础层相同,确保更高的安全性和最终确认性。
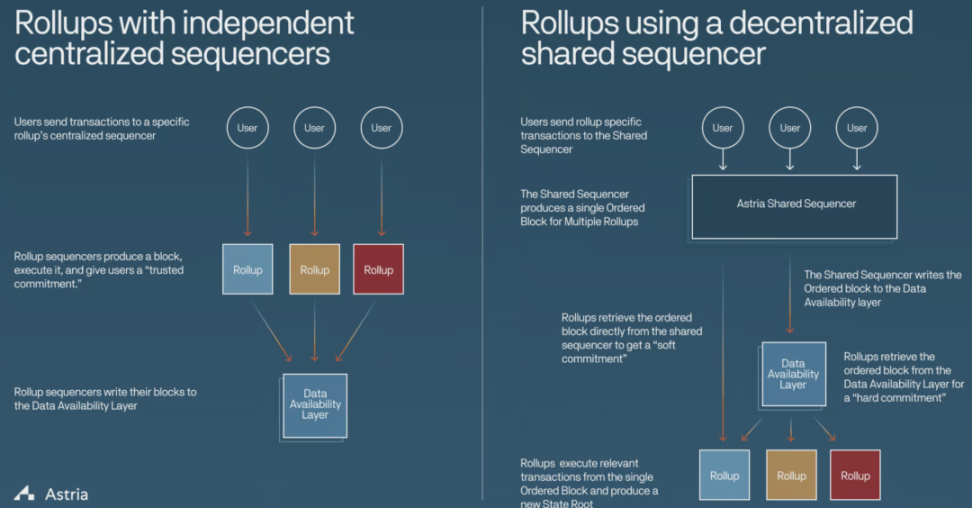
Espresso

Espresso 在零知识技术领域做出了重大贡献。他们最新在开发一种去中心化排序器的综合解决方案,可应用于 Optimistic Rollups 和 zkRollups。
去中心化排序器网络由以下组成:
- HotShot 共识:优先考虑高吞吐量和快速最终确认性,而不是动态可用性。
- Espresso DA:结合基于委员会的 DA 解决方案和 VID,其中高带宽节点将数据提供给所有其他节点。每个单独区块的可用性也由小型随机选举的委员会支持。VID 提供可靠但较慢的备份,只要所有节点的足够高比例的质押权重没有受到威胁,就可以保证可用性。
- Rollup REST API:以太坊兼容 JSON-RPC。
- 排序器合约:验证 HotShot 共识(即作为轻客户端)并记录 checkpoints(即对交易进行密码学承诺),管理 HotShot 的质押表。
- P2P 网络:Gossip 协议。
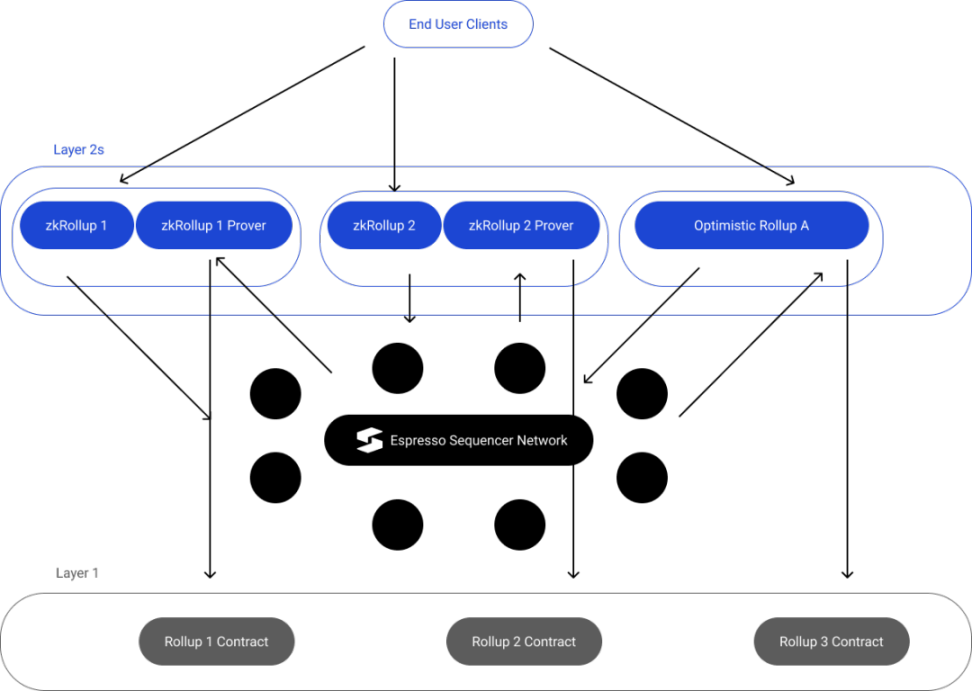
与 Astria 相比,Espresso 提供 DA。因此,工作流程将略有不同,如下所述:
1. 用户创建并提交交易到 Rollup。
2. 交易通过排序器网络传播并保留在内存池中。
3. 通过 HotShot 质押机制指定领导者,提出区块,并将其传播回 Rollup 的执行者和证明者。
4. 领导者将交易发送到数据可用性委员会,并收到 DA 证书作为反馈。
5. 领导者还向 Layer 1 排序器合约发送对区块的承诺,以及合约用于验证区块的证书。
Espresso 引入了用于证明的 Gossip 协议,提供更灵活的用户体验。它提供三种交易最终确认性的选项:
- 快速:用户可以信任已执行交易并生成证明的 Rollup 服务器,或者他们可以利用 HotShot 的低延迟执行交易。
- 适度:用户可以稍等一段时间以生成证明,然后检查该证明。
- 慢速:用户可以等待 L1 验证状态更新来获取更新后的状态,无需任何信任假设或计算。
除了上述优化之外,Espresso 还计划使整个以太坊验证者集本身参与运行 Espresso 排序器协议。使用相同的验证者集合将提供类似的安全性,并且与 L1 验证者分享价值将更加安全。此外,Espresso 还可以利用 EigenLayer 提供的 ETH 再质押解决方案。
Radius

Radius 正在构建一个基于零知识证明的无信任共享排序层,专注于解决 L2 中的 MEV 问题,因为 L2 的收入主要来自区块空间。所需要考虑的权衡是 MEV 和 L2 收入之间的平衡。Radius 的目标是消除对用户有害的 MEV,并提出了一个两层服务。
顶层针对常规用户交易,并通过使用时间锁谜题提供密码学保护,以防止有害的 MEV。具体而言,它采用了实用可验证延迟加密(PVDE)技术,该技术将在 5 秒内为基于 RSA 的时间锁谜题生成零知识证明。该方法提供了一种实用的解决方案,以保护用户免受有害的 MEV。简而言之,在排序器确定交易顺序之后,才可以知晓交易内容。
底层是为区块构建者设计的,并允许他们参与产生收入的活动,同时减轻 MEV 的负面影响。
Based Rollups

Based Rollup 是最近由 Justin Drake 提出的一个概念,其中 L1 区块提议者与 L1 的搜索者和构建者合作,在无需许可的情况下将 rollup 区块包含在下一个 L1 区块中。它可以被视为 L1 上的共享排序器网络。Based Rollup 的优缺点很明显。
从积极的一面来看,Based Rollup 利用了 L1 所提供的活性和去中心化性,并且它的实现简单且高效。Based Rollup 也与 L1 保持经济上的一致性。然而,这并不意味着 Based Rollup 损害了其主权。虽然将 MEV 交给了 L1,Based Rollup 仍然可以拥有治理代币并收取基础费用。根据假设,Based Rollup 可以利用这些优势,实现主导地位,并最终最大化收益。
结论

观察所提出的这些方案,可以看出 Rollup 的去中心化仍有很长的路要走。其中一些提案仍处于草案阶段,需要进一步讨论,而其他一些则仅完成了初步规格说明。所有这些方案都需要实现并接受严格的测试。
虽然有些 Rollup 可能没有明确提出相应的去中心化解决方案,但它们通常包括应急逃离机制来解决由于中心化排序器引起的单点故障。例如,zkSync 提供了`FullExit`方法,允许用户直接从 L1 提取其资金。在系统进入exodus mode ,无法处理新区块时,用户可以启动提款操作。
为了实现抗审查,这些 Rollup 通常还允许用户直接在 L1 上提交交易。例如,zkSync 采用优先级队列来处理在 L1 上发送的这类交易。类似地,Polygon zkEVM 在 L1 合约中包含了一个 force batch 方法。当一周内未发生聚合时,用户可以在 L1 上调用此方法,并提供交易的字节数组和bathFee 给证明者。
可以肯定的是,在可预见的未来,Rollup 的去中心化将会是一个组合型的解决方案,可能包括上述这些重要的方案或者其他一些创新性的变体。
参考资料
https://wiki.polygon.technology/docs/zkEVM/
https://ethresear.ch/t/proof-of-efficiency-a-new-consensus-mechanism-for-zk-rollups/11988/12
https://community.starknet.io/t/starknet-decentralization-kicking-off-the-discussion/711
https://docs.minaprotocol.com/node-operators/scan-state
https://blog.nil.foundation/2023/04/26/proof-market-and-zkllvm-pipeline.html
https://ethresear.ch/t/shared-sequencer-for-mev-protection-and-profitable-marketplace/15313
https://hackmd.io/@EspressoSystems/EspressoSequencer
https://hackmd.io/@EspressoSystems/SharedSequencing
https://ethresear.ch/t/based-rollups-superpowers-from-l1-sequencing/15016
https://research.arbitrum.io/t/challenging-periods-reimagined-the-key-role-of-sequencer-decentralization/9189
{kind=link}